Hash tables
Hash tables là một cấu trúc dữ liệu hiệu quả cho việc lưu trữ và truy vấn dữ liệu. Ý tưởng là đưa vào một giá trị key, sử dụng một hash function để sinh ra một hash value năm trong một vùng integer cho trước, ví dụ NHASH là size của một hash table. Một hash function tốt khi phân phối được đồng đều tất cả các keys vào các vị trí hash value (bucket), có thể là một chuỗi các phần tử có cùng hash value. Trong trường hợp tốt nhất thì việc cập nhật và truy vấn là O(1), trong trường hợp xấu nhất thì sẽ là O(N), khi N phần tử được chèn vào duy nhất một bucket.
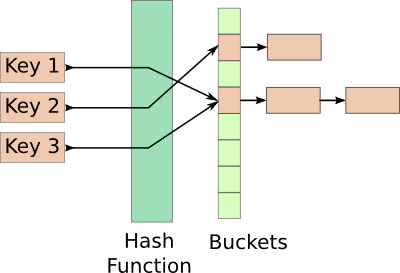
Một hash table là một mảng của danh sách các phần tử, kiểu của phần tử là giống nhau danh sách đó. Có thể khai báo như sau:
typedef struct {
char *name;
int value;
Nameval *next; /* in chain */
} Nameval;
Nameval *symtab[NHASH]; /* a symbol table */
Một hash function thì sẽ tính toán hash value như thế nào? Một function hash lý tưởng cần phải nhanh và phân phối dữ dự đồng đều vào các bucket. Một trong những thuật toán hashing cho string phổ biến để sinh một hash value bằng cách lặp qua các ký tự trong chuỗi nhân giá trị hash với một số nguyên tố và cộng với giá trị của ký tự đó. Cuối cùng trả về modulo của kích thước hash table. Trong thực nghiệm thì giá trị nguyên tố sử dụng đưa lại kết quả tốt là 31 và 37.
enum { MULTIPLER = 31 };
/* hash: compute hash value of string */
unsigned int hash(char *str) {
unsigned int h;
unsigned char *p;
h = 0;
for (p = (unsigned char *)str; *p != '\0'; p++)
h = MULTIPLIER * h + *p;
return h % NHASH
}
Bởi vì dữ liệu không được phân phối đều, trong khi đó hash function có những share factor như là MULTIPLIER và NHASH. Khi MULTIPLER là một số nguyên tốt, thì chúng ta nên chọn NHASH cũng là một số nguyên để đảm bảo dữ liệu có thể được phân bố tốt hơn. Nhiều bạn có thể đặt câu hỏi tại sao sử dụng số nguyên tốt mà không phải một số nào khác. Đặc điểm của số nguyên tốt là duy nhất và chỉ chia hết cho 1 và chính nó. Vì vậy khi nhân hay chia một số cho số nguyên tốt, chúng ta có cơ hội cao hơn để nhận về một số có thể là duy nhất (uniqueness).
Một điểm đáng chú ý của hashing trong bài báo của Gerard Holzmann về bit state hashing. Thay vì sử dụng hash table với một danh sách tại mỗi bucket. Holzmann sử dụng một mảng siêu lớn để chứa thông tin về một trạng thái của một state trong một chương trình concurrent programs. Đưa vào một state, sử dụng hash function để trả về một vị trí trong mảng siêu lớn. Nếu giá trị tại mảng đó là 0, nghĩa là state đó chưa được thăm, ngược lại là đã được thăm. Việc xung đột là không thể tránh khỏi và hệ thống sẽ bỏ qua vì đây là cách làm xấp xỉ. Vì vậy cần phải thiết kế hash function cẩn thận để việc xung đột xảy ra ở mức thấp. Holzmann đã sử dụng cyclic redundancy check một hàm có thể sinh ra một hash value với sự kết hợp của toàn bộ dữ liệu.
Enjoy Reading This Article?
Here are some more articles you might like to read next: